7papers|ICCV2019最佳论文;滴滴提出「语音版」BERT
时间:2019-11-03 13:54:10 热度:37.1℃ 作者:网络
机器之心整理
参与:一鸣、杜伟
本周,ICCV 2019 最佳论文出炉,同时还有滴滴提出的语音预训练模型,FaceBook 的 BART 预训练语言模型等。
目录:
- Pre-training only embedding matrix for new language is good enough for transfer learning - new paper from Deepmind
- Omni-Scale Feature Learning for Person Re-Identification
- SinGAN:Learning a Generative Model From a Single Natural Image
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
- Deep Learning vs. Traditional Computer Vision
- Seeing What a GAN Cannot Generate
论文 1:Re-training only embedding matrix for new language is good enough for transfer learning - new paper from Deepmind
- 作者:Mikel Artetxe、Sebastian Ruder、Dani Yogatama
- 论文地址:https://arxiv.org/pdf/1910.11856.pdf
摘要:当前的 SOTA 无监督多语言模型(如多语言 BERT)已被证明可以在零样本跨语言设置下实现泛化。这种泛化能力得益于共享的子字语法和跨多种语言的联合训练,从而产生了深度多语言抽象。在本文中,来自巴斯克地区大学和谷歌 DeepMind 的三位研究者设计了一种在词汇层面将单语言模型迁移到新语言的替代方法,对以上假设进行了评估。具体而言,他们首先训练了针对单一语言、基于 Transformer 的掩码语言模型,并通过学习到一个具有相同掩码语言建模目标(即冻结其他所有层的参数)的新嵌入矩阵将该模型迁移到新的语言。这一替代方法不依赖共享的语言或联合训练。研究表明,该方法在标准的跨语言分类基准以及一个新的跨语言问答数据集(Cross-lingual Question Answering Dataset,XQuAD)与多语言 BERT 的性能相当。此外,研究结果驳斥了多语言模型泛化能力基础的普遍观点,并表明深度单语言模型学习到了可以实现跨语言泛化一些抽象。
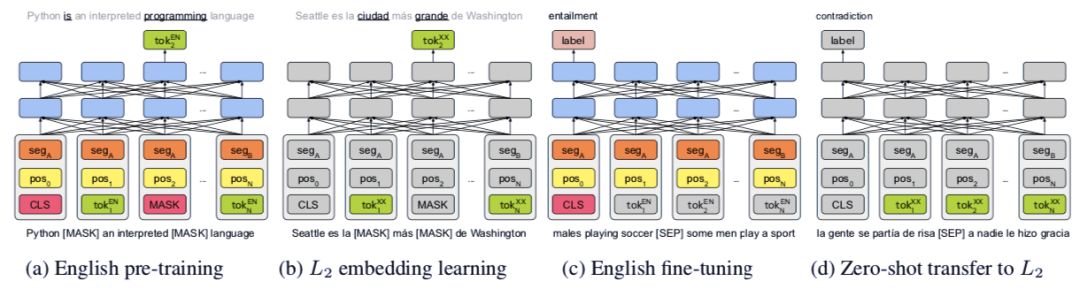
图 1:零样本跨语言迁移的四步骤:(i)训练一个类似于 BERT 的单语言(英语)transformer 模型;(ii)冻结 transformer 主体并通过运用英语语料库上的同一训练目标从零开始为第二种语言学习新的 token 嵌入;(iii)微调英语 transformer 模型,同时保持嵌入冻结;(iv)通过交换 token 嵌入将该模型零样本迁移到新的语言。
推荐:如何用迁移学习快速构建新语言的模型?过去需要从头开始预训练,但是这也许不是必要的。DeepMind 的这篇最新论文说明,只需要一部分层的预训练即可。
论文 2:Omni-Scale Feature Learning for Person Re-Identification
- 作者:Kaiyang Zhou、Yongxin Yang、Andrea Cavallaro、Tao Xiang
- 论文地址:https://arxiv.org/pdf/1905.00953.pdf
- 项目地址:https://github.com/KaiyangZhou/deep-person-reid
摘要:作为一个实例级识别问题,人体再识别(personal re-identification,ReID)依赖于差异特征,其不仅可以捕获不同的空间尺度,而且能够封装多尺度的任意组合。我们通常将同构和异构尺度的特征称为全尺度(omni-scale)特征。在本文中,来自萨里大学、伦敦玛丽女王大学和剑桥三星人工智能中心(SAIC-Cambridge)的四位研究者设计了一种用于全尺度特征学习的深度 ReID 卷积神经网络(CNN),他们称之为全尺度网络(Omni-Scale Network,OSNet)。这是通过设计包含多个特征卷积流的残差块来实现的,每个卷积流检测一定尺度内的特征。重要的是,他们提出了一种新颖的统一聚合门(unified aggregation gate),以动态融合多尺度特征以及与输入相关的通路级权重。为了有效地学习到空间-通路的相关性并避免过拟合,构建块使用了逐点和深度卷积。通过逐层堆叠此类构建块,研究者提出的 OSNet 非常轻量级,并可以在现有的 ReID 基准上从零开始进行训练。尽管模型尺寸较小,但 OSNet 在 6 个人体 ReID 数据集上均实现了 SOTA 性能,大大超越了多数大尺寸模型。

图 1:以上四组图像表明人体再识别是一个难题。每个图像中,左边是检索图像,中间是真实匹配,右边是冒充者/假匹配。
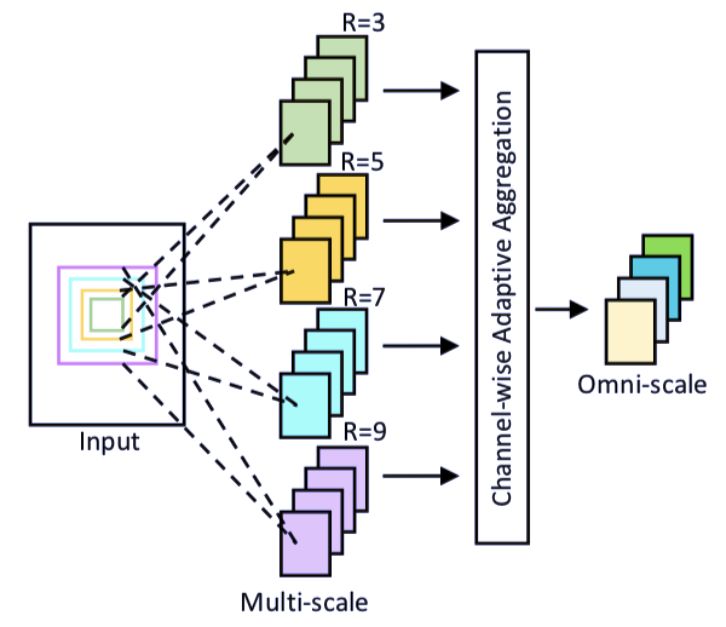
图 2:全尺度网络(OSNet)的构建块图解。R 表示接受域大小。
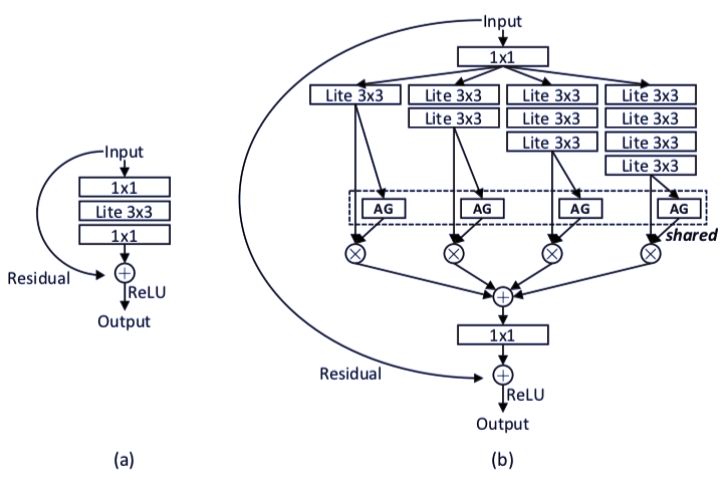
图 4:(a)基线瓶颈;(b)本文提出的瓶颈。AG 表示聚合门。第一个/最后一个 1×1 层用于降低/修复特征维数。
推荐:行人再识别一直是图像方面的重点研究领域。本文是最新的 SOTA 论文,读者可参考了解最新的研究进展。
论文 3:SinGAN:Learning a Generative Model From a Single Natural Image
- 作者:Tamar Rott Shaham、Tali Dekei、Tomer Michaeli
- 论文链接:http://openaccess.thecvf.com/content_ICCV_2019/papers/Shaham_SinGAN_Learning_a_Generative_Model_From_a_Single_Natural_Image_ICCV_2019_paper.pdf
- 项目地址:https://github.com/tamarott/SinGAN
摘要:在这篇论文中,研究者介绍了一种无监督的生成模型 SinGAN,它以一种无条件约束的方式从单张自然图像中学习知识。经过训练,研究者的模型能捕捉图像块(patch)的内部分布,从而生成高质量、多样化的样本,并承载与训练图像相同的视觉内容。SinGAN 包含一个全卷积金字塔 GAN,金字塔的每一层负责学习不同比例的图像块分布。这样就能生成具有任意大小和横纵比的新样本,这种生成样本明显具有可变性,但同时又能保持真实图像的全局结构与精细纹理。与之前的单图像 GAN 相比,研究者的方法不仅能生成纹理图像,同时它还以一种无条件约束的方式生成。研究者在最后还表明,SinGAN 生成的图像经常被人类弄混,它们与真实图像没什么差别。

图 1:SinGAN 通过使用多尺度对抗训练方案,从多种尺度学习了图像块信息。这样一来,模型就可以生成新的真实图像样本,其中在创建新的目标属性和结构的同时还保留了原始的图像块分布信息。如上展示了不同尺度图像的生成效果。
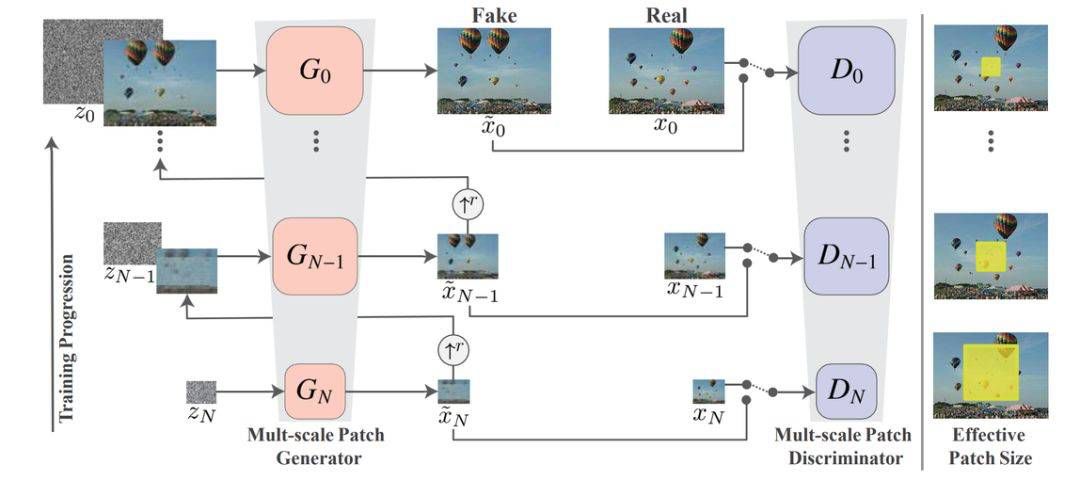
图 4:SinGAN 的多尺度生成流程,模型由 GAN 的一种金字塔方案组成,每一层都是一个生成对抗网络,它们从下到上学习着不同尺度的图像生成效果。SinGAN 的训练和推断过程都是从粗粒度到细粒度的方向进行。
推荐:本文是 ICCV 2019 最佳论文。提出的金字塔式的 GAN 网络较为少见,是一种新颖的方法。
论文 4:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- 作者:Mike Lewis 等
- 论文链接:https://arxiv.org/pdf/1910.13461.pdf
摘要:近日,Facebook 发表论文,提出一种为预训练序列到序列模型而设计的去噪自编码器 BART。BART 通过以下步骤训练得到:1)使用任意噪声函数破坏文本;2)学习模型来重建原始文本。BART 使用基于 Transformer 的标准神经机器翻译架构,可泛化 BERT(具备双向编码器)、GPT(具备从左至右的解码器)等近期出现的预训练模型,尽管它非常简洁。Facebook 研究人员评估了多种噪声方法,最终通过随机打乱原始句子的顺序,再使用新型文本填充方法(即用单个 mask token 替换文本段)找出最优性能。BART 尤其擅长处理文本生成任务,不过它在理解任务中的性能也不错。在提供同等的训练资源时,BART 可在 GLUE 和 SQuAD 数据集上实现与 RoBERTa 相当的性能,并在抽象对话、问答和文本摘要等任务中获得新的当前最优结果,在 XSum 数据集上的性能比之前研究提升了 6 ROUGE。在机器翻译任务中,BART 在仅使用目标语言预训练的情况下,获得了比回译系统高出 1.1 个 BLEU 值的结果。研究人员还使用控制变量实验复制了 BART 框架内的其他预训练机制,从而更好地评估影响终端任务性能的最大因素。
图 1a:BERT:用掩码替换随机 token,双向编码文档。由于缺失 token 被单独预测,因此 BERT 较难用于生成任务。

图 1b:GPT:使用自回归方式预测 token,这意味着 GPT 可用于生成任务。但是,该模型仅基于左侧上下文预测单词,无法学习双向交互。
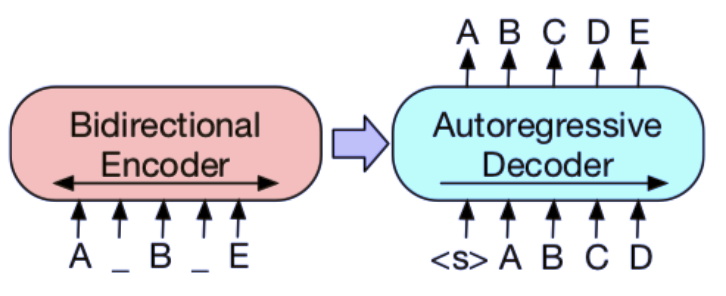
图 1c:BART:编码器输入与解码器输出无需对齐,即允许任意噪声变换。使用掩码符号替换文本段,从而破坏文本。使用双向模型编码被破坏的文本(左),然后使用自回归解码器计算原始文档的似然(右)。至于微调,未被破坏的文档是编码器和解码器的输入,研究者使用来自解码器最终隐藏状态的表征。
推荐:本文是预训练模型的又一前沿研究。通过结合 BERT 和 GPUT-2 两种模型的优点,使得模型在部分自然语言处理任务上取得了新的 SOTA。论文采用的思想可参考。
论文 5:Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
- 作者:Adji B. Dieng、Francisco J. R. Ruiz、David M. Blei、Michalis K. Titsias
- 论文链接:https://arxiv.org/pdf/1910.09932.pdf
摘要:语音识别技术在各种工业应用中获得了极大的普及。但是,建立一个好的语音识别系统通常需要大量的转录数据,而这些数据收集起来成本高昂。为了解决这个问题,来自滴滴出行人工智能实验室的研究者提出了一种新颖的无监督预训练方法,他们称之为 masked 预测编码(masked predictive coding,MPC)。这种方法可以应用于基于 Transformer 模型的无监督预训练。
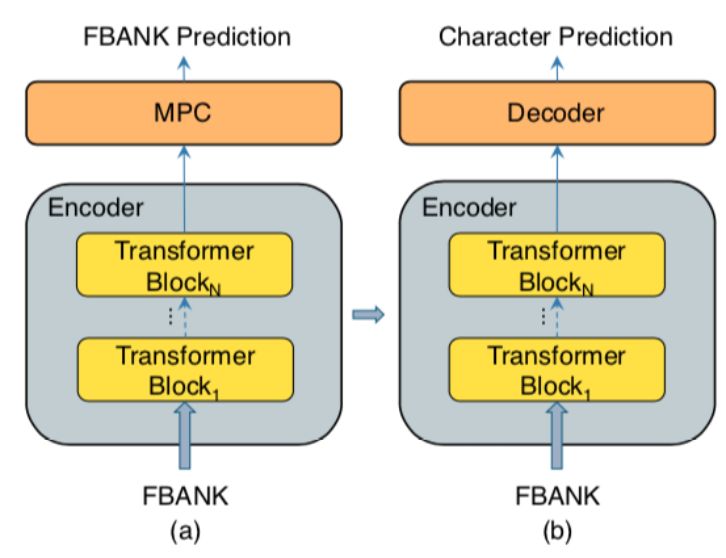
图 1:研究者提出的训练流程。(a)预训练:编码器预测被 mask 的位置,从而预测 FBANK。(b)微调:Transformer 解码器在编码器之后加入,然后模型微调用于预测字符。
在预训练时,降采样在输入特征被输入到编码器进行预训练之前使用。而降采样在微调过程中是在模型内部进行的。
推荐:预训练语言模型的成功说明,Transformer 架构具有很大的优势。本文中,滴滴的研究者们考虑在语音预训练模型中尝试了同样的方法。结果说明,预训练模型的思路是正确的,有继续探索的潜力。
论文 6:Deep Learning vs. Traditional Computer Vision
作者:Niall O』 Mahony、Sean Campbell、Anderson Carvalho 等
论文链接:https://arxiv.org/pdf/1910.13796.pdf
摘要:深度学习已经推动到了数字图像处理领域的发展极限。但是,这并不是说在深度学习兴起之前的几年中,一直在逐步发展的传统计算机视觉技术已经过时了。在本文中,研究者将分析每种方法的优缺点,其目的在于深入探讨是否应保留经典计算机视觉技术的相关知识。本文还将探讨如何将计算机视觉的两个方面结合起来。此外,本文回顾了近期的几种混合方法,证明了这些方法有能力提升计算机视觉性能并解决深度学习所不能解决的问题。例如,传统计算机视觉技术与深度学习的结合已经在全景视野和三维视觉等新兴领域流行开来,而单独的深度学习模型在这些领域中尚未实现完全优化。
推荐:本文是计算机视觉领域的综述和回顾论文。作者对比了深度学习和传统方法的优缺点,并提出了相应的应用领域。
论文 7:Seeing What a GAN Cannot Generate
- 作者:David Bau、Jun-Yan Zhu、Jonas Wulff、William Peebles 等
- 论文链接:https://arxiv.org/abs/1910.11626v1
- 项目地址:https://ganseeing.csail.mit.edu
摘要:生成对抗网络(GAN)现在已经能合成极具真实感的图像了,但 MIT、IBM 和香港中文大学的一项研究表明 GAN 在合成图像时会遗漏目标分布中的一些细节。未来的 GAN 设计者如果能够充分考虑这种遗漏情况,应该能够打造出更加高质量的图像生成器。研究者已经公布了相关论文、代码和数据。MIT 的这项研究在分布层面和实例层面对模式崩塌进行了可视化。
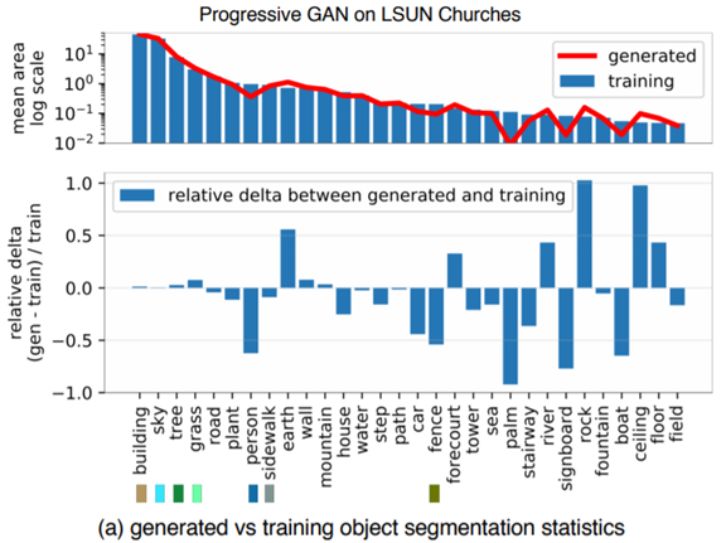
图 1a 展示了在一个教堂 GAN 模型中,相比于训练分布,人、车和栅栏等目标类别在生成分布中出现的像素更少。

图 1:看 GAN 不能生成什么:(a)作者比较了 LSUN 教堂训练集中的目标分割分布与生成结果的分布:生成器丢弃了人、车和栅栏等目标。(b)一张真实图像及其重建图像的比较,其中一个人和栅栏的实例无法生成。每组图中,左上角的是真实照片,右上角的是生成的重建图像,下面两张是各自的分割映射图。
推荐:GAN 究竟在做什么?这是研究者经常思考的问题。本文通过研究 GAN 的生成结果,了解这种模型及其变体的特点,并提出了可行的改进建议。

