AI+K8S驱动存储技术变革
时间:2019-10-31 17:37:15 热度:37.1℃ 作者:网络
在以容器为应用运行载体的Kubernetes平台上,运行AI训练和推理任务,正逐步成为AI厂商以及AI应用在企业落地的热点和首选。这两年,国内外陆续有相关的研究报告在关注这两个前沿技术的结合和突破,与之相关的工具和创新型企业也不断涌现。
Gartner 在2019年发布的一份关于AI的预测报告中指出,在过去的一年里,采用AI的企业数量增加了两倍,而AI成为了企业CIO们考虑的头等大事。CIO在企业内实施AI应用的过程里,必须考虑的五个要素中就有两项与Kubernetes相关:
第一,AI将决定基础架构的选型和决策。在企业对AI的使用正在迅速增加的背景下,到2023年,人工智能将成为驱动基础架构决策的主要工作负载之一。加快AI的落地,需要特定的基础设施资源,这些资源可以与AI以及相关基础设施技术一起同步发展。我们认为,以Kubernetes强大的编排以及对AI模型的支持能力,通过在互联网厂商以及更多客户总结的最佳实践,Kubernetes将成为企业内部AI应用首选的运行环境和平台。
第二,Serverless将得到更大发展。容器和Serverless将使机器学习模型作为独立的功能提供服务,从而以更低的开销运行AI应用。Gartner直接指出了将容器作为机器学习模型的优势和趋势。
关于机器学习,你要知道的事
为了更深入地理解这一技术趋势,我们需要对人工智能、机器学习有基本的理解。
机器学习是人工智能(AI)的分支,它使计算机系统能够使用统计方法,识别或学习大量数据中存在的规律和模式。机器学习将这些模式汇总到一个模型中,通过该模型,计算机就能进行预测或执行具体的识别任务,而无需人为地编写规则来实现对输入数据的识别和处理。简单地说,机器学习是对数据进行处理、统计和归纳,是数据处理的科学。
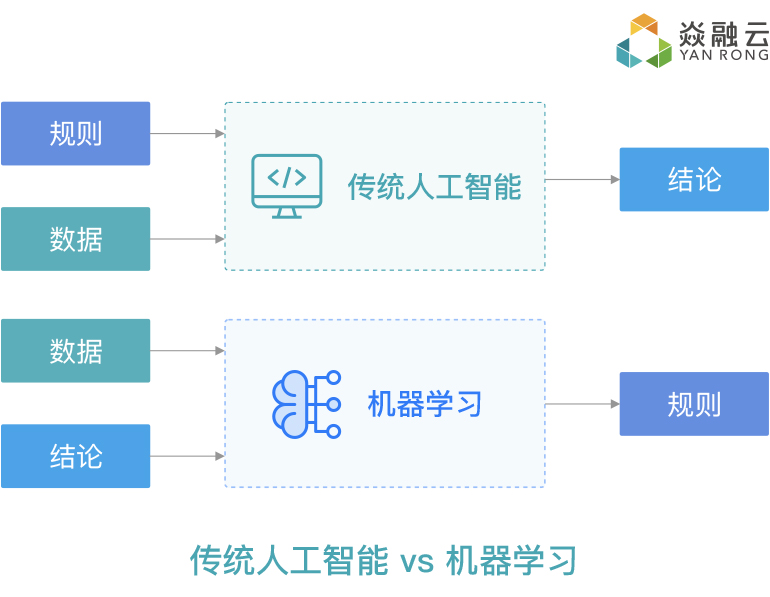
现代的机器学习需要依赖特定的算法,虽然这些算法大多数在数十年前就已经存在了,但算法的存在并没有使机器学习在那些年就被重视和认可。直到近些年,可用于训练的数据和负担得起的计算能力爆炸式增长、模型训练方法的进步、以及用于开发机器学习解决方案的工具数量和质量飞速增长,才使得人工智能得以快速发展。
我们可以注意到,从基础架构角度,除了强大的算力(云和GPU居功至伟)之外,推动机器学习向前发展的两大动力,一是强(爱)大(省事)的程序员们编写了大量支撑机器学习的框架和工具,二是海量的数据成为可能。
机器学习在平台架构上面临的挑战
机器学习只有达到一定规模,才能将模型训练得更为精准,要使机器学习快速扩展规模,工程团队会面临以下的挑战:
1、数据的管理与自动化
在探索性机器学习的应用里,数据科学家或机器学习工程师需要花费大量时间手动构建和准备新模型所需的数据,如何保护和管理这些耗费大量时间资源获取和准备的数据,本身就是一个需要考虑的问题。
其次,将各种数据转换、特征工程和ETL pipeline进行自动化,对于提高建模效率和反复运行机器学习任务是非常必要的。自动化pipeline除了对建模过程有很大帮助之外,对推断时为生产模型提供现成的特征数据也起着至关重要的作用。
此外,数据和特征的转换会不断形成新的数据,这些新数据通常不仅需要保留用于训练,还会用于将来的推断过程。因此,提供可伸缩、高性能的数据存储和管理是支持机器学习过程的团队所面临的重大挑战,底层的存储系统需要支持训练和推理工作负载所需的低延迟和高吞吐量访问,避免反复进行数据复制。
2、有效利用资源
今天,计算能力空前强大,诸如高密度CPU内核,GPU和TPU之类的硬件创新正越来越多地服务于机器和深度学习工作负载,从而保证了这些应用程序的计算资源在持续增长。
然而,尽管计算成本在不断下降,由于机器学习的过程实质上是对数据的高密度处理和 应用机器学习面临的挑战。
3、底层技术架构的复杂性
PaaS产品和DevOps自动化工具的兴起,使软件开发人员可以专注于正在开发的应用程序,而不必担心应用程序所依赖的中间件和基础设施。
同样,为了使机器学习过程能够充分发挥规模和效率,数据科学家和机器学习工程师必须能够专注于模型和数据产品的构建和优化,而不是基础架构。
人工智能建立在快速发展的复杂技术栈上,包括TensorFlow、PyTorch等深度学习框架,SciPy,NumPy和Pandas等特定语言库以及Spark和MapReduce等数据处理引擎。这些工具由NVIDIA的CUDA等各种底层驱动程序和库支持,使AI任务可以利用GPU,而正确安装和配置这些基础架构非常困难。如何选择一个良好的基础架构,才能帮助AI科学家从这些复杂的技术栈中解放出来,将精力投入到模型的优化中,是AI企业取得成功的关键。
Kubernetes为何成为机器学习青睐的支撑平台
Kubernetes如何化解AI平台面临的挑战
容器和Kubernetes借助开源的力量,获得巨大发展,通过大量实践,证明了这一技术确实能够帮助AI企业应对上述几个的挑战。
1、数据管理与自动化
Kubernetes提供了将存储连接到容器化工作负载的基本机制,持久卷PV提供了使Kubernetes支持有状态应用程序(包括机器学习)的基本支持。
基于这些支持,AI企业就可以使用各种与Kubernetes紧密集成的第三方解决方案来构建高度自动化的数据处理pipeline,从而确保无需人工干预就能可靠地完成数据转换。
恰当的存储产品可以使Kubernetes工作负载获得分布式存储系统中数据的统一访问,内部团队也不再需要通过多种数据访问方式来获取数据,并实现数据和特征跨项目共享的目标。
2、有效利用资源
Kubernetes能够跟踪不同工作节点的属性,例如存在的CPU或GPU的类型和数量,或可用的RAM数量。在将作业调度到节点时,Kubernetes会根据这些属性,对资源进行有效分配。
对于机器学习这种资源密集型工作负载,Kubernetes最适合于根据工作负载随时自动扩展或收缩计算规模,相对于虚拟机或物理机而言,通过容器完成扩展和收缩更为平稳、快速、简单。
此外,通过Kubernetes的命名空间的功能,可以将单个物理Kubernetes集群划分为多个虚拟集群,使单个集群可以更轻松地支持不同的团队和项目,每个名称空间都可以配置有自己的资源配额和访问控制策略,满足复杂的多租户需求,从而能更充分地利用各种底层资源。
3、隐藏复杂性
容器提供了一种独立于语言和框架的,有效打包机器学习工作负载的方式,Kubernetes则提供了一个可靠的工作负载编排和管理平台,Kubernetes通过必要的配置选项、API和工具来管理这些工作负载,从而使工程师可以通过yaml文件,即可控制这些上层应用。
使用容器封装数据机器学习任务的另一个好处,是这些工作负载本身的依赖问题已经封装在容器的声明里,从而屏蔽掉机器学习任务对底层技术栈的依赖。这样,无论在开发者笔记本电脑、训练环境还是生产集群上,这些AI任务都可以正确地保持依赖关系并顺利运行。
Kubernetes+机器学习的良好生态系统
Kubernetes已经成为云原生时代编排框架的事实标准,各种资源、任务都可以使用Kubernetes进行编排和管理,当然也包括机器学习任务。基于Kubernetes,大量开发者和公司已经提供了众多开源或商业的工具(包括:Argo、Pachyderm、Katib、KubeFlow、RiseML等),通过这些工具,AI公司可以进一步提升机器学习任务在Kubernetes上运行的效率,增强使用Kubernetes进行机器学习的能力。
另一方面,很多Kubernetes开源版本或商业发行版都支持基于Kubernetes对GPU进行很好的调度和管理,在数据分析和计算层面上看,这为机器学习与Kubernetes的结合扫清了障碍。
机器学习运行在Kubernetes上对存储系统提出了哪些要求
前面提到过,机器学习快速发展的两大动力,一是框架和工具的支持,这一点已经通过Kubernetes以及类似TensorFlow、PyTorch、KubeFlow等工具实现;二是机器学习必须依赖海量的数据。在Kubernetes被机器学习广泛接受和使用的背景下,机器学习对海量数据的存储系统提出了哪些要求?结合对多个一流的AI企业的交流和了解,我们发现以下一些特点:
1、机器学习需要依赖海量的数据,这些数据基本都是以非结构化的文件形式存在,例如数十亿张图片、语音片段、视频片段等,存储系统需要能支持数十亿规模的文件。
2、这些文件大小通常在几百KB到几MB之间,存储系统需要保证小文件的高效存储和访问。
3、由于上层的机器学习任务是通过Kubernetes进行管理和调度,这些任务需要访问的存储也要通过Kubernetes进行分配和管理,存储系统需要对Kubernetes进行很好的适配和支持。
4、多个机器学习任务经常需要共享一部分数据,意味着多个Pod需要共享访问(读写)一个PV,底层存储系统需要支持RWX访问模式。
5、机器学习需要使用到GPU等计算资源,存储系统在海量小文件前提下,需要能提供足够的多客户端并发访问性能,才能使GPU资源得到充分利用。
YRCloudFile如何应对Kubernetes+机器学习的场景
我们可以从Kubernetes支持以及机器学习的数据特点两个维度来分析YRCloudFile在这一新型场景上的优势。

YRCloudFile从设计到实现,首要场景就是解决Kubernetes环境中,容器化应用对存储的访问需求,也借此成为国内首个入选CNCF LandScape Container-Native Storage的存储产品。为此,YRCloudFile支持:
1、CSI、FlexVolume的访问插件。通过CSI插件,在对Kubernetes没有任何侵入的前提下,Kubernetes可以为机器学习应用申请独立或共享的存储资源。
2、支持数百个Pod同时访问同一个PV资源,并能够将这些Pod快速并发拉起,满足机器学习的多个任务共享访问数据(RWX读写模式)的要求,解决了基于块存储方案在这方面的天然缺陷。
3、在机器学习任务的Pod需要跨节点重建时,Pod可以在新节点上快速访问到原有数据,无需人为干预和接入,完全满足自动化的基本诉求,块存储容器解决方案在这方面也存在不足。
其次,在机器学习海量小文件的数据特点上,YRCloudFile相对于其它开源或商业产品也具有明显优势:
4、 YRCloudFile在数十亿小文件规模下,无论文件操作性能(重点考验元数据处理能力),或者是小文件读写带宽(重点考察元数据处理和存储的并发访问性能),都保持平稳的性能。相较于其它传统的云原生存储或分布式文件存储,YRCloudFile在海量小文件的支持上,都具有优势。
5、在机器学习场景下,网络的选择和性能尤为重要,以Mellanox为代表的网络供应商,在InfiniBand通信协议上,针对机器学习做了大量优化,提供了GPUDirect、SHARP等高级的网络特性。YRCloudFile完全支持在InfiniBand、RoCE网络环境下运行,并提供比传统TCP网络环境更高的读写性能,从而更好地支持机器学习任务。
通过这篇文章,我们可以清晰地看到Kubernetes在人工智能、机器学习这一新型应用场景下得到快速应用的趋势,并深入理解了这个趋势背后的技术推动力。同时,我们也了解到Kubernetes+机器学习的结合,对数据的存储系统提出了哪些新的需求,YRCloudFile在这一新场景和趋势下,所凸显出的优势更为明显。目前,YRCloudFile已经在一流的AI企业中得到了实践和应用。YRCloudFile会结合在实际生产环境中发现的机器学习对数据访问的具体特点,进行更深层次的优化,在这个崭新的应用场景中扩大领先地位,继续助力AI企业提升机器学习的效率和水平。

