当博弈论遇上机器学习:一文读懂相关理论
时间:2019-10-28 14:04:37 热度:37.1℃ 作者:网络
机器之心原创
作者:王子嘉
编辑:Joni Zhong
博弈论和机器学习能擦出怎样的火花?本文作者王子嘉通过回顾总结近年来博弈论和机器学习领域的交叉研究工作,为读者展示了这一领域最新的研究图景。
「博弈论」这个词可能对于一些仅仅致力于机器学习前沿算法的人并不算熟悉。其实,有意无意的,博弈论的思想一直存在于很多机器学习的探索过程中,不管是经典的 SVM,还是大火的 GAN,这些模型的背后都有博弈论的影子。
近年来,随着机器学习的发展,机器学习要应用的场景越来越复杂,开始有人有意识的将博弈论与机器学习联系起来。总的来说,博弈论在机器学习研究中的作用主要有三个:(1) 解释机器学习模型的原理与思想;(2) 建立合适的学习策略;(3) 预测人类参与者(人机交互时)的行为。基于这三个方面,本文首先解释了博弈论的基本概念及其如何解释机器学习中的一些模型,然后介绍了博弈论在 Multi-Agent Reinforcement Learning(MARL)中的应用,最后介绍了博弈论与机器学习结合所产生的新分支——博弈机器学习。
博弈论是什么
严格来说,博弈论主要是研究理性决策者之间的冲突与合作的数学模型。这个定义有些抽象,没接触过博弈论的人也很难很直观的从「博弈论」这个名字知晓博弈论到底是什么。这个词可以拆开来看,「博弈」这个词很多时候是出现在围棋、战争等场景中,再看一下博弈论的英文——「Game Theory」,那么博弈论就很好理解了,就是一个研究怎么合理玩好这个世界中存在的各种游戏的学科。
具体来说,博弈论涉及到的「游戏」主要可以根据 5 个特征分类:合作性(游戏中人是否可以与他人联合)、对称性(玩家们是否有相同的目标)、信息完整性(能否知道其他玩家的决策与动向)、同步性(玩家的动作是同时进行的,还是一个玩家的动作是在另一个玩家的动作之后的)以及零和性(一个玩家得分是否会导致另外一个玩家减分)。以台球(斯诺克)为例,这个游戏是无法与他人合作的(非合作性),玩家们具有相同的目标(将桌上的球按一定规则击入袋中,对称性),玩家可以知道对面玩家的动向(信息完整性),每个玩家需要在另一个玩家击球失败后开始自己的击球(非同步性),因为红球数是一定的,从某种程度上来说,一个玩家的得分会导致另外一个玩家得分期望的减少,故而本游戏是零和游戏。基于这些分类,不同的方法论可以应用在不同的游戏中,比如纳什均衡(后文会解释)在对称性游戏中更容易达到。
要注意的是,这里的「游戏」不一定只指传统意义上的游戏,如下图所示,它包括很多方面。很多问题都可以被看作是「游戏」,这在本质上跟人工智能就是互通的了——AI 的终极目的就是让电脑也能玩转人类正在玩或者将要开始玩的一些游戏。看一下下图,博弈论所研究的领域与 AI 正在研究的领域何其相似,再回忆在民众间打响 AI 名声的 AlphaGo,也正是从游戏着手,去学习人类的思考模式。所以当博弈论遇上机器学习,一些很奇妙的「化学反应」就会发生——解释了一些数学模型的意义、出现了一些新的探索方向,等等。

图源 http://euler.fd.cvut.cz/predmety/game_theory/
博弈论与机器学习
很多在博弈论中出现的概念都被引用到了机器学习中,纳什均衡(Nash Equilibrium, NE)就是其中一个。这是指的游戏中的一个状态,在这个状态下,在其他玩家决策不变的情况下,如果任何一个玩家改变当下的决策,都无法得到更多的好处。换句话说,如果所有人都把自己的决策告诉其他玩家,其他玩家都不会变更自己的方案,这时候就达到了 NE。这极其类似于机器学习中的最优解。对于 NE,最经典的例子就是囚徒困境 (prisoner's dilemma),如下图所示。这个例子中,有两个犯人被抓住了,这两个犯人都被单独提审,无法提前串通。在这种情况下
- 如果两个囚犯中的一个供认另一个犯了罪,则供认出对方的人将被释放,而另一个将被判处 10 年徒刑;
- 如果他们俩都不认罪,他们每个人被判一年监禁;
- 如果他们都承认,他们都将被判处 5 年徒刑。
在这个例子中,很容易就可以看出当两个人都供出对方时达到了本游戏的 NE。在这个状态下,任意一个人改变自己的决策,就会面临 10 年的监禁。

图源:https://towardsdatascience.com/game-theory-in-artificial-intelligence-57a7937e1b88
传统的机器学习大多被看作优化问题,我们需要做的就是找到一个能够搜索最优解的算法。但是,机器学习与传统优化问题的不同在于,我们希望通过机器学习得到的模型不会过度拟合数据,这样就可以在尚未遇到的情况中也有很好的表现。也就是说,我们希望这些机器对未知数做出预测,这种要求我们一般称之为泛化,这也是为什么深度学习中的许多工程需要对优化问题附加约束的原因,这些约束有些文章称之为「先验」,在优化问题中则被称为正则化。
这些正则化来自哪里,我们如何选择良好的正则化?我们如何处理不完全的信息?这个时候,博弈论的思想就很重要了。泛化有时被称为「结构风险最小化」。换句话说,我们就是不知道验证集数据的情况下,降低训练集风险的策略来构建机制来处理泛化。
在机器学习,尤其是分类方法中,很多大家熟悉的传统方法都有博弈论的影子。SVM 就可以看作一个双人的零和博弈,这种优化类的机器学习算法就可以看作是寻找一个 NE(每个类选择一个超平面),在这个平面存在的情况下,可以最好的完成分类任务;线性回归可以看作是一个非合作博弈,每个类都希望自己的损失最低;Adaboost 则可以看作是利用合作、非同步博弈论进行在线学习。
当然,体现博弈最明显的算法就是 GAN 中的对抗学习了。先回顾一下 GAN 的结构,GAN 有两个部分——一个生成器,一个判别器(如下图所示)。生成器尽自己最大的努力去欺骗判别器,而判别器则是尽自己最大的努力判别图片是否是生成器生成的。在提出 GAN 的原始论文中有说明过这是一个 MinMax 游戏,而最终的目标就是找到这个游戏的 NE,但论文中并没有明显的提及这个游戏的分类,因此 GAN 虽然有博弈论的影子,但是没有彻底的继承博弈论的优点,所以 GAN 很难训练,而且训练出的结果也很难判断是否是鞍点。所以现在也有一些研究开始聚焦如何把 GAN 具象成一个更具体的游戏,从而使得结果更好。比如在 GANGs: Generative Adversarial Network Games 中,作者就提出了一种 GAN game,明确的将 GAN 定义为零和游戏。
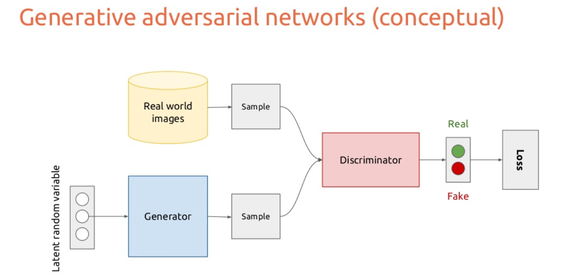
图源:https://sigmoidal.io/beginners-review-of-gan-architectures/
这个过程非常类似于一个双人游戏。在这个游戏中,我们的玩家(两个模型)互相挑战,第一个伪造样本以混淆另一个玩家,而第二个创建者则试图在识别正确的样本方面变得越来越好,并反复重复此游戏,并在每次迭代中更新学习参数,以减少总损失(有更多的经验)。而最终训练的目的是找到这个游戏的 NE,这个时候两个模型都已经最大程度上的完成了自己的任务,无法再进行改进了,任何参数的更新都会导致自己损失的增加。
博弈论与强化学习——Multi-Agent Reinforcement Learning(MARL)
强化学习(Reinforcement Learning,RL)旨在通过与环境(可以是虚拟的也可以是真实的)的交互来使智能体(我们的「模型」)学习。RL 一开始是根据 Markov 过程提出的,我们让智能体处于不确定的固定环境中,并试图通过奖励/惩罚机制来学习到一个最优策略。在单智能体的情况下,这种方法被证明是收敛的。
但是,如果是将多个智能体放置在同一环境中(多智能体强化学习,MARL),情况就复杂多了。假设我们正在试着用智能车来改善城市的交通情况。这时每辆车的决策都会影响其他车的决策与表现,比如智能车与智能车之间很可能会发生冲突,因为可能对于两辆智能车而言,沿着某条路线行驶都是最方便的(获得最多的奖励)。
MARL分类
上面例子中,智能体之间倾向于竞争关系。实际生活中,智能体之间的关系还可能是合作关系,或半合作半竞争(mixed)。智能体间复杂的关系和智能体之间的影响让 MARL 变得极其复杂。这个时候,博弈论的引入就会让建模变得轻松很多,在这种情况下,我们可以把智能车看作不同的玩家,而此时 NE 则代表不同智能车之间的平衡点。具体来说,MARL 可以分成三种「游戏」:
- 静态游戏 (static games): 静态游戏中,智能体无法知道其他智能体所做的决策,故而我们可以认为所有智能体的决策是同步,相互之间不受影响。
- 动态游戏 (stage games): 动态游戏中有很多不同的阶段,每个阶段都是一个游戏(stage game),上面提到的囚徒困境就可以看作其中一个阶段的游戏。
- 重复游戏 (repeated games): 如果一个 MARL 系统中各个阶段的游戏都很相似,那么就可以被称为重复游戏。

图源:https://towardsdatascience.com/modern-game-theory-and-multi-agent-reinforcement-learning-systems-e8c936d6de42
基于博弈论的 RL 算法(Alphastar)
当下,博弈论除了理论上的作用外,基于博弈论提出的 RL 算法也在大放异彩。比如掌控了星际争霸的 AlphaStar 的开发过程中就充满了博弈论的影子。星际争霸作为一个游戏,就像剪刀石头布一样,很难得到一个单一的最佳方案,是永远在博弈中的,要对当下的已有的策略进行学习,并选择最好的那个。
AlphaStar 所参考的算法就是 Double Oracle Algorithm(DO Algo),这个算法将目标定为寻找当下 stage game 的 NE。DO Algo 的原理如下图所示。它使用深度神经网络进行函数逼近,迭代计算子游戏的收益矩阵(Gt)。这个子游戏就是上文提到的 stage games。在每个时间 t 处(每个 stage game),都会计算出符合 NE 的回应(σ),并得到最优策略(π),然后添加新的策略来扩展 Gt 为 Gt + 1,继续重复上述过程。
以下图为例,开始两个玩家的收益矩阵 Gt 很像刚刚举的囚徒案例,π代表各个玩家可以采取的策略,初始的 Gt 中各个玩家只有两个策略(比如两个玩家各有两个进攻计划,佯攻和攻击分矿),然后通过求 NE 响应来获得两个玩家在这个场景下能得到的最佳相应 P1,P2。这时,两个玩家都发现,对现有的进攻计划都不是很有信心,希望拖入后期,于是玩家继续从自己的策略库中选择策略加入到 Gt 中(比如开分矿),从而得到 Gt+1,然后此时对应的 P1,P2 又被计算出来。总的来说就是在当下的 stage game 中计算 NE 响应,再根据情况扩展游戏,再计算,直到你对结果变得有信心为止。

图源:https://medium.com/@gema.parreno.piqueras/a-unified-game-theoretic-approach-to-multi-agent-reinforcement-learning-4b291b786446
当然,星际争霸远比我现在说的要复杂的多,策略要千变万化的多,比如假若你真的选择拖后期,如何选择后期单位(是巢虫领主、雷兽、航母、风暴战舰、雷神或者战列巡航舰这种很肉又很强力的单位,还是飞蛇、高阶圣堂武士或者幽灵这样辅助性的施法单位),如何跟对方交换中期单位才不导致自己损失过大,这些都是要考虑的问题。所以如果直接将 DO Algo 应用在星际争霸这样的游戏中,在 DO Algo 中使用动作作为策略,那策略会有很多。
因此,在 AlphaStar 所应用的核心算法文献 A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning 中,他们就将 DO Algo 进行了泛化(Policy-Space Response Oracles,PSRO),策略将不再只能是单个动作,也可以是战术或者其它的 meta-solver,同时提出了 Deep Cognitive Hierarchies(DCH)来解决游戏中策略规模的问题。
其中 PSRO 如下图所示,该算法首先抽样一个初始策略并计算效用函数,并初始化元策略(记录策略分布的函数),元游戏开始于一个单一的策略,并在每个 epoch 中添加策略(也就是算法名字中的 Oracle),这些策略将尽可能地响应其他玩家的元策略。请注意,该算法存在计算量问题,因为对于每个 epoch、每个 player 和 episode,都需要基于每个 player 计算新的策略 pi 和元策略。不是计算确切的最佳响应,而是使用 RL 计算近似的最佳响应。

图源:https://medium.com/@gema.parreno.piqueras/a-unified-game-theoretic-approach-to-multi-agent-reinforcement-learning-4b291b786446
强化学习的每一个 step 都可能需要很长时间才能收敛到好结果,而有些已经学过的东西可能会在后面的学习过程中再学一遍,为了解决 PSRO 中计算量过大的问题,这篇论文又提出了 DHC 算法以使得 PSRO 并行化。具体来说,就是不再挨个 epoch 进行训练,而是预先确定 K 个 level(代替 epoch),并开启 NK 个线程(N 为玩家数),每个线程训练一个玩家的一个 oracle,并将结果定期保存到中央存储器中。每个线程还会有当前 level 或者更低 level 的策略信息(类似后面的 epoch 知晓前面 epoch 的训练结果)。由此可见,DHC 牺牲了准确性(减少了 epoch 数)以换取其可扩展性(减少计算量)。

图源:https://arxiv.org/pdf/1711.00832.pdf
可以看出,这个算法是博弈论与 RL 算法密切结合的产物,它已经被应用在 AlphaStar 并获得了巨大的成功,由此可见,博弈论所代表的 RL 学习策略是很值得信赖的。
运算量的简化
当系统有大量的智能体的时候,建模可能会变得非常困难,因为智能体数量的增加会使不同智能体间交互方式的数量成倍增加。在这中情况下,博弈论中提出的的 Mean Field Games 为 MARL 模型建模提供了目前来说最好的方案。MFG 中会假定各个玩家的活动都是相似的,因此如果一个 RL 场景可以被转换成 MFG 场景,那么一开始就可以假设所有智能体都具有相似的奖励方程,这样就可以大大降低 MARL 模型的复杂性。
很多论文已经在研究这一点,其中在 Reinforcement Learning for Mean Field Game 中,就探究了如何 action coupled 的随机博弈环境中寻找 Mean Field Equilibrium(MFE)。假设其他因素的影响可以通过行为均值的分布来确定,而且所有的智能体都知道行动的分布,并利用近期最佳响应来选择最优的遗忘策略。文中提出了一种基于后验抽样的均值场(Mean Field)博弈强化学习方法,其中每个智能体从之前的转移矩阵中抽取一个转移概率。文中证明了策略分布和行为分布分别收敛于最优的遗忘策略和极限分布,并共同构成了一个 MFE。
博弈机器学习
在博弈论中还存在一个概念叫做逆博弈论(Inverse Game Theory)。博弈论旨在了解游戏的动态,以优化其玩家可能获得的结果。相反的,逆博弈论旨在根据玩家的策略和目标来设计游戏。逆博弈论在多智能体 AI 以及人机交互 AI 中都很有用处。
2013 年国际人工智能大会(IJCAI)上,微软亚洲研究院刘铁岩博士所在的团队首次提出了「博弈机器学习」的概念,这是将博弈论与机器学习结合而产生的新分支,即以博弈论的思想对人的动态策略进行显式建模,利用行为模型和决策模型相结合的方式来解决这一类难题。有了博弈机器学习,我们的算法就可以比人多想一步、甚至多想很多步,提前预料对方会做出什么样的反应,从而在与之博弈的时候占得先机。
刘铁岩博士在介绍博弈机器学习的文章中写道:「真实的人类行为既非随机、也非完全理性和对立——事实上人类(智能体)的行为往往会有一定规律可循。与前面提到的这些技术不同,博弈机器学习就是利用了这样一个简单的常识。无论是人与人之间的互动,还是人与计算机之间的互动都是可以被建模的,这样我们就能够知道这些人为的数据是如何产生的,从而在学习的过程中对此加以利用,从而在和人类博弈的过程中占得先机。」
由此可见,博弈机器学习可以在广告竞价、社交媒体、众包管理、交通疏导等很多领域中被应用。一旦我们在机器学习的过程中,对人的行为模型做出学习和描述,就可以知道我们的算法机制发生改变之后,人们的行为会怎么去改变,从而知道在很长时间以后当人的行为趋于稳定(均衡态),我们取得的结果是好是坏。
在 A Game-theoretic Machine Learning Approach for Revenue Maximization in Sponsored Search 中,刘铁岩博士就是用博弈机器学习在广告竞价任务上得到了很好的效果。从下面这张图中可以看出,这个算法使用了双层优化框架来学习拍卖机制。
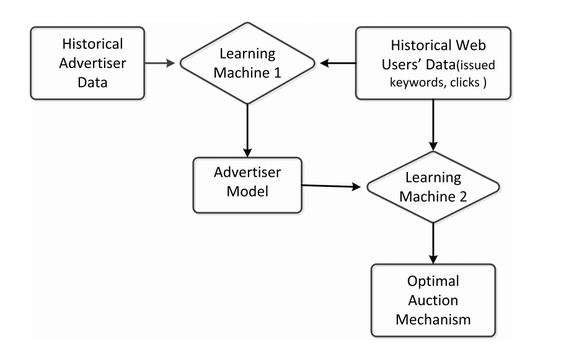
图源:https://arxiv.org/pdf/1406.0728.pdf
具体的算法如下图所示,首先从历史数据中学习一个马尔可夫模型,以描述广告商如何响应拍卖机制以更改其出价,然后对于任何给定的拍卖机制,都使用学习的模型来预测其相应的未来出价顺序。然后就可以通过对预测出价序列进行经验收益最大化来学习拍卖机制。结果表明,当预测时间接近无穷大时,收益将收敛,并且遗传算法可以有效地优化该收益。文中的实验表明,与几种基准相比,本算法能够产生更有效的拍卖机制。

图源:https://arxiv.org/pdf/1406.0728.pdf
总结
「什么才是人工智能?想要解决这个问题,首先需要为「智能」提出一个定义。如果说过去对于个体智能的研究为计算机赋予了智商(IQ)的话,那么社会智能则对应着人工智能的情商(EQ)。」
最后还是引用刘铁岩博士的这句话作为结尾,博弈论的引入让智能体在过去与环境打交道的基础上又学会了如何与其他智能体打交道,如何与人打交道。同样的,博弈论作为研究各种游戏、人、社会、经济等的理论,它的思想几乎无处不在,不仅仅在那些明明白白提出结合博弈论的算法中,一些常见的算法中也常常藏着博弈论思想的影子。或许博弈论也是联系机器学习走向人和社会的一个桥梁。
作者介绍:本文作者为王子嘉,目前在帝国理工学院人工智能硕士在读。主要研究方向为 NLP 的推荐等,喜欢前沿技术,热爱稀奇古怪的想法,是立志做一个不走寻常路的研究者的男人!
参考文献
Rezek I, Leslie D S, Reece S, et al. On similarities between inference in game theory and machine learning[J]. Journal of Artificial Intelligence Research, 2008, 33: 259-283.
Game Theory in Artificial Intelligence. Accessed at : https://towardsdatascience.com/game-theory-in-artificial-intelligence-57a7937e1b88
Game Theory reveals the Future of Deep Learning. Accessed at: https://medium.com/intuitionmachine/game-theory-maps-the-future-of-deep-learning-21e193b0e33a
刘铁岩:博弈机器学习是什么 ? Accessed at: https://www.open-open.com/lib/view/open1470471285206.html
Modern Game Theory and Multi-Agent Reinforcement Learning Systems. Accessed at : (https://towardsdatascience.com/modern-game-theory-and-multi-agent-reinforcement-learning-systems-e8c936d6de42)https://towardsdatascience.com/modern-game-theory-and-multi-agent-reinforcement-learning-systems-e8c936d6de42
A Unified Game-Theoretic Approach to Multi-agent Reinforcement Learning. Accessed at: https://medium.com/@gema.parreno.piqueras/a-unified-game-theoretic-approach-to-multi-agent-reinforcement-learning-4b291b786446
Di He, Wei Chen, Liwei Wang, and Tie-Yan Liu. A game-theoretic machinelearning approach for revenue maximization in sponsored search.CoRR,abs/1406.0728, 2014.
Frans A. Oliehoek, Rahul Savani, Jose Gallego-Posada, Elise van der Pol,Edwin D. de Jong, and Roderich Gross. GANGs: Generative AdversarialNetwork Games.arXiv e-prints, page arXiv:1712.00679, Dec 2017.
Mridul Agarwal, Vaneet Aggarwal, Arnob Ghosh, and Nilay Tiwari.Reinforcement Learning for Mean Field Game.arXiv e-prints, pagearXiv:1905.13357, May 2019.
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

