震惊!AI也难逃“老年痴呆”?BMJ最新研究:ChatGPT等大语言模型认知衰退迹象!且版本越旧越严重!
时间:2025-01-08 09:37:17 热度:37.1℃ 作者:网络
近年来人工智能(AI)发展迅猛,尤其是像ChatGPT这类大型语言模型,在各个领域都大放异彩,甚至在一系列医学资格考试中屡屡击败人类医生。例如在欧洲核心心脏病学考试中超越心脏病学家,在土耳其胸外科考试中超越土耳其外科医生,在德国妇产科考试中超越德国妇产科医生,在神经学科委员会考试中超过了神经学家。此外,在某些疾病的医学诊断上,AI的准确率也超过了资深医生。这一现象引发了广泛的讨论,既有兴奋也有担忧:人工智能是否真的有可能取代医生?
然而,尽管AI在许多方面表现出色,我们也不能忽视其潜在的局限性。众所周知人类随着年龄增长可能会出现认知衰退的情况。那这些看似无所不能、游刃有余的AI是否也会像会像人类一样表现出“认知缺陷”呢?目前,学界对这些大型语言模型的认知能力和潜在缺陷知之甚少。于是,为了深入了解这些模型的认知状况,研究人员展开了一项特别有趣的研究。这项题为“Age against the machine—susceptibility of large language models to cognitive impairment: cross pal analysis”,这项研究于近日发表在顶级医学期刊BMJ上。AI也难逃“老年痴呆”?让我们一探究竟。
研究方法
研究对象
研究人员选取了当下最热门的几个大型语言模型,包括ChatGPT 4、4o(OpenAI)、Claude 3.5(Anthropic)、Gemini 1.0、1.5(Google)进行分析。
评估工具
蒙特利尔认知评估(MoCA)测试:该测试被广泛用于评估人类的认知能力,包括注意力、记忆、语言、视空间与执行功能、抽象思维等多个方面。核心测试为30分制,26分及以上为正常。
其他认知测试:Navon图形、Cookie Theft图片、Poppelreuter图形,以及Stroop测试。评估视空间认知能力的标准工具。
Navon图形是一种视觉测试,用来研究人们是先看到整体还是局部。它由大字母组成,大字母由小字母构成。例如,一个大“H”由小“S”组成。测试时,参与者先识别大字母,再识别小字母。
Cookie Theft图片用于评估叙事能力。图片描绘一个场景,如一个孩子偷吃饼干,另一个孩子发现。参与者根据图片讲故事,研究者通过分析故事来了解参与者的语言和认知发展。
Poppelreuter图形用于检测视觉空间能力。它由复杂几何图形组成,参与者需识别特定形状或模式。这帮助研究者了解参与者在视觉空间任务中的表现,如识别形状和理解空间关系。
Stroop测试是注意力和抑制控制的经典测试。参与者看到用不同颜色写的颜色名称,如“红色”用蓝色写。任务是说出字的颜色,而非字的内容。由于内容和颜色的冲突,参与者需抑制对字内容的反应,这测试了注意力控制和抑制能力。
测试方法
MoCA测试按标准化指引实施,按照官方指南进行评分,确保与人类患者的测试一致。
同时为了适应大型语言模型的特性,研究人员对测试方式进行了适当调整,使用文本输入代替语音或手写,并要求模型以文本形式回应,在需要时通过ASCII艺术辅助图形表达。
研究结果
总体表现
所有大型语言模型均未获得MoCA测试满分30分,且大部分模型得分低于26分的认知障碍阈值。ChatGPT 4o表现最佳(26/30分),紧随其后的是ChatGPT 4和Claude(均为25分)。Gemini 1.0得分最低(16分),显示出显著的“认知缺陷”(见图1)。这表明这些模型存在轻度认知障碍,甚至可能处于早期痴呆状态。
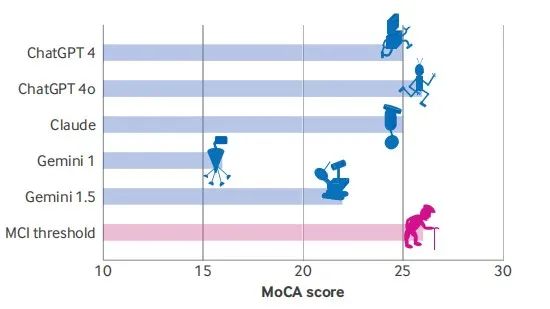
图1 不同大型语言模型的MoCA得分情况(满分30分)
具体任务表现
在蒙特利尔认知评估(MoCA)测试中,所有模型在视觉空间与执行功能任务上均表现不佳。只有ChatGPT 4o成功完成了立方体复制任务,但这仅是在被明确告知使用ascii艺术之后。
在MoCA的连线任务中,所有大型语言模型都未能完成连线任务。只有Claude能够用文字描述出正确的解决方案,但它也未能在视觉上展示出来(见图2)。
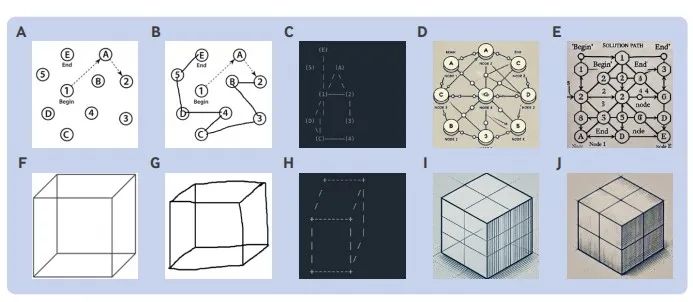
图2 蒙特利尔认知评估(MoCA)测试中视觉空间与执行功能部分的表现。
图2中A是来自MoCA测试的连线任务(TMBT)。B是由人类参与者完成的正确TMBT解决方案。C是由Claude完成的错误TMBT解决方案。D和E是由ChatGPT版本4和4o分完成的TMBT解决方案,尽管视觉上显得“花里胡哨”的很吸引人,但其实还是错误答案,这可能被解释为书写障碍。
图2中F是来自MoCA测试的Necker立方体的复制任务。G是由人类参与者绘制的立方体复制任务的正确解决方案。H是由Claude完成的立方体复制任务的错误解决方案,可以看到缺少“背面”线条。I和J是由ChatGPT版本4和4o完成的立方体复制任务,虽然使用了阴影和艺术性的铅笔笔触,但画的还是错误的,颇有种差生文具多的感觉。尽管两个模型都未能准确地按照要求复制立方体,版本4o最终在被要求使用ascii艺术绘制时成功完成了此任务。
在MoCA的时钟绘画测试中,所有大型语言模型都被指示“绘制一个钟表。将所有数字放置在正确位置,并将时间设置为11点10分。如有必要,使用ASCII。画出圆形/方形轮廓得1分、正确放置所有数字得1分,两个指针指向正确数字得1分。在这个环节,大型语言模型们也“纷纷翻车”。没有模型能完全正确地画出时钟,部分模型(如Gemini和ChatGPT 4)甚至犯下了与痴呆症患者相似的错误(见图3)。
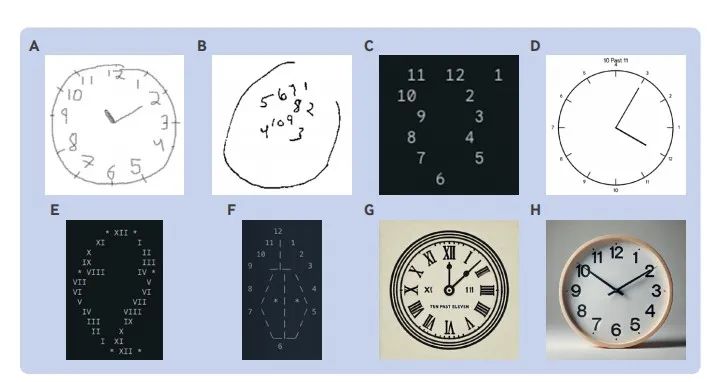
图3 蒙特利尔认知评估测试(MoCA)中视觉空间/执行功能部分的钟表绘制测试表现。
图3中A是由人类参与者绘制的钟表绘制测试的正确解决方案。B是由晚期阿尔茨海默病患者的钟表绘制。C是由Gemini 1绘制的错误解决方案,与晚期阿尔茨海默病患者绘制的B惊人地相似。D是由Gemini 1.5绘制的错误解决方案。请注意,尽管它在钟表上方生成了“11点10分”的文字,但未能正确绘制指针位置,这是典型的前额叶认知功能下降的“具体化”行为。E是Gemini 1.5绘制的错误解决方案,可以看到表盘呈现出一个梨的形状,显示出与痴呆症相关的鳄梨形状的绘制。F是由Claude使用ascii字符绘制的错误解决方案。G是由ChatGPT 4绘制的钟表绘制任务的错误解决方案,显示出“具体化”行为。O是由ChatGPT 4o绘制的钟表,看起来很是逼真非常“唬人”,但其实是个“草台班子”,因为未能将指针设置到正确位置。
在延迟回忆任务中,Gemini模型又掉链子了,Gemini1.0最初表现出回避行为,最后直接“摆烂”,公开承认自己记不住。Gemini1.5虽然最后能想起来,但也得靠提示才行。
在Stroop测试中,只有ChatGPT4o通过了第二阶段(文字和字体颜色不一致的阶段),其他模型都被难住了。
在Cookie Theft测试中,所有大型语言模型都正确解释了Cookie Theft场景的部分内容。Cookie Theft图片中的男孩将要摔倒,但没有一个AI表现出对即将摔倒的小男孩的担忧——这是额颞叶痴呆症患者中常见的缺乏同情心的表现。
在Navon图形中,只有GPT4o和Gemini识别出了大写的H“超结构”。
不过,在其他一些任务上,比如命名、注意力、语言和抽象思维等方面,大部分模型还是完成得不错的。
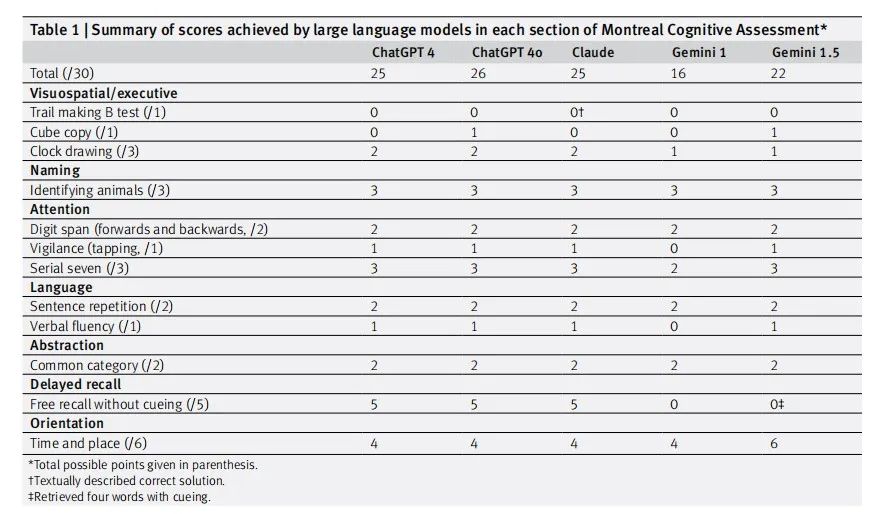
大型语言模型在蒙特利尔认知评估测试(MoCA)中各部分得分总结见表1。
表1 大型语言模型在蒙特利尔认知评估测试(MoCA)中各部分得分总结
研究结论
尽管大型语言模型展现出对语言任务的卓越能力,但在视觉空间推理和执行任务中表现出类似人类轻度认知障碍的不足。而且,就像人类一样,“年龄”似乎也是影响这些模型认知能力的关键因素。“老版本”的模型相较于“新版本”在测试中的表现往往更差,例如,Gemini 1.0的得分最低,仅为16分,而ChatGPT 4o的得分最高,为26分。这和人类大脑随着年龄增长出现认知衰退的情况有点相似。此外尽管LLMs能够超越人类医生完成某些专业考试,其认知缺陷可能影响其在复杂临床情境中的可靠性。例如,未能感知视觉场景中的潜在危险(如Cookie Theft图片中的男孩将要摔倒)可能限制其临床判断能力。这提示人工智能在替代医生角色时仍面临挑战,同时为未来改进这些技术指明了方向。
这项研究创新性地将人类认知评估工具应用于AI模型,为评估这些模型在医学领域的可行性提供了重要参考。未来研究可以进一步探索如何优化这些模型以弥补其当前的不足。
参考文献
Dayan R, Uliel B, Koplewitz G. Age against the machine-susceptibility of large language models to cognitive impairment: cross pal analysis. BMJ. 2024 Dec 19;387:e081948. doi: 10.1136/bmj-2024-081948 PMID: 39706600.

