分割一切的视觉算法出现,病理和影像的人工智能可能会被颠覆!
时间:2023-04-10 20:08:27 热度:37.1℃ 作者:网络
Meta研究部门发布了一篇名为其“Segment Anything(分割一切)”的论文,文中介绍了一个全新的Segment Anything Model(即SAM),可以用于识别图像和视频中的物体,甚至是人工智能从未被训练过的物品。
所谓的“分割”,用最通俗的话来说就是抠图。但Meta此次所展示的人工智能抠图能力,可能远比你想象的要更加强大,甚至在人工智能领域被认为是计算机视觉的“GPT-3时刻”。
此次SAM的一大突破还在于即使是在训练过程中从未遇到过的物品和形状,人工智能也能将其准确识别并分割出来。

英伟达人工智能科学家 Jim Fan 表示此次SAM最大的一点突破是它已经基本能够理解“物品”的一般概念,即使对于未知对象、不熟悉的场景(例如水下和显微镜里的细胞)它都能比较准确的理解。因此他表示相信SAM的出现会是在计算机视觉领域里的GPT-3时刻。
不仅是Jim有这样的观点,一些AI研究专家甚至也表示,SAM之于计算机视觉,就像是GPT之于大语言模型。
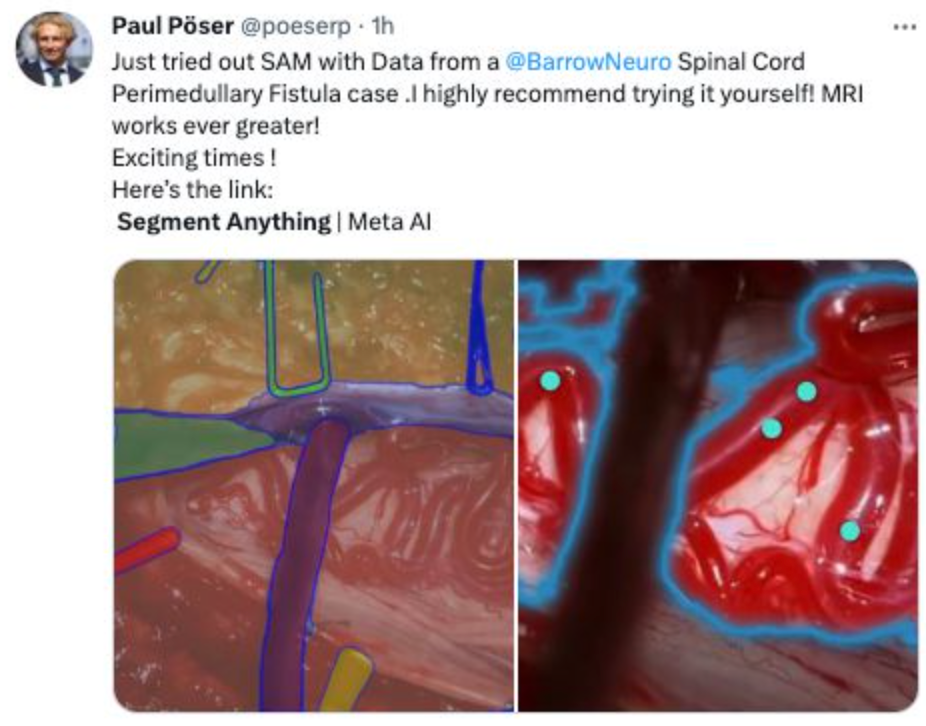
有神经外科影像学的专家将SAM用到了一个脊髓血管病的病例文件之中,认为SAM在帮助判断和分析病情上有很大帮助。

有生物学家输入了一张显微镜下的组织图片,即使图中形状特征毫无规律,但凭借着Zero-shot技术,SAM也能够自动识别多细胞结构中的腺体、导管、动脉等。该生物学家认为SAM的产出结果已经非常接近完美,未来能够节省大量手动注释的时间。

几乎同时,国内的智源研究院视觉团队也提出了通用分割模型SegGPT——Segment Everything in Context,首个利用视觉上下文完成各种分割任务的通用视觉模型。
SegGPT “一通百通”:可使用一个或几个示例图片和对应的掩码即可分割大量测试图片。用户在画面上标注识别一类物体,即可批量化识别分割出其他所有同类物体,无论是在当前画面还是其他画面或视频环境中。
SAM“一触即通”:通过一个点、边界框或一句话,在待预测图片上给出交互提示,识别分割画面上的指定物体。这也就意味着,SAM的精细标注能力,与SegGPT的批量化标注分割能力,还能进一步相结合,产生全新的CV应用。
参考资料:
https://research.facebook.com/publications/segment-anything/
https://segment-anything.com/
论文地址:https://arxiv.org/abs/2304.02643
论文地址:https://arxiv.org/abs/2211.07636
最新资讯
热门文章

-
国家药监局与沙特食品药品监督管理局签署合作谅解备忘录
国家药监局与沙特食品药品监督管理局签署合作谅解备忘录

-
国家药监局与丹麦药品管理局签署合作意向书le
国家药监局与丹麦药品管理局签署合作意向书le
- BMJ:海南医科大学杨国静发布基于真实世界数据与GBD 2021估算的中国被忽视热带病负担差异研究(2004-2020年)
- Rheumatology:多生物标志物疾病活动评分,监测类风湿关节炎的客观工具
- JHLT:持续性左心室辅助装置(LVAD)支持下左心室反应的纵向分析
- CLIN CANCER RES | Trop-2 在转移性尿路上皮癌患者中高表达,并可作为戈沙妥珠单抗治疗的潜在靶点
- 协和医学杂志:近红外光谱技术在心肺复苏中的应用进展
- 糖心共病时代,如何进行共病精细化管理?
- Blood Cancer Journal :苏州大学吴德沛/薛胜利教授团队探索全新CAR-T联合自体造血干细胞移植治疗B-ALL方案,安全有效!
- Radiology:弥散MRI预测乳腺癌分子亚型和对新辅助化疗治疗反应的能力及价值