用户界面开发自动化,新研究根据设计图自动生成用户界面属性|一周AI最火论文
时间:2020-01-06 15:20:22 热度:37.1℃ 作者:网络

大数据文摘专栏作品
作者:Christopher Dossman
编译:Junefish、Olivia、云舟
呜啦啦啦啦啦啦啦大家好,本周的AI Scholar Weekly栏目又和大家见面啦!
AI ScholarWeekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
每周更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:伪造人脸、无监督学习、模仿学习
本周最佳学术研究
X射线检测伪造人脸图像
北京大学和微软亚洲研究院的研究人员最近推出了人脸X射线图像表示法,用于检测人脸图像中的伪造,该方法大大超过了目前已有的最新方法。

他们的工作重点是检测面部伪造问题,例如由当前的面部操纵算法(包括DeepFakes,Face2Face,FaceSwap和NeuralTextures)产生的伪造问题。
与现有的伪造检测器不同,面部X射线假定存在混合步骤,并且不依赖于与特定面部操纵技术相关的任何伪造图像知识。通过对输入的面部图像进行计算,可以得到该图像面部X射线的灰度图像。该灰度图像不仅可以确定面部图像是伪造的还是真实的,而且在存在混合边界时,还可以确定该边界的位置
我们必须承认人脸伪造检测正日益成为一项严峻的挑战。面部X射线检测方法在面部伪造识别方面实现了非常高的检测精度,并且能够可靠地预测面部X射线,因此,它是普遍面部伪造检测器开发征程上的重要一步。
对于未预见的人脸操纵方法产生的伪造,该框架仍然有效。与之形成对比的是,大多数现有的人脸伪造检测算法则会有相当大的性能下降。
面部X射线的通用性涵盖了大多数现有的面部操作算法。此外,可以通过自我监督学习来训练用于计算面部X射线的算法,该训练过程无需任何最新的面部操作方法生成伪图像,仅使用大量由真实图像合成的混合图像即可实现。
阅读更多:
https://arxiv.org/abs/1912.13458v1
同步进行的无监督学习:条件图像生成,前景分割和细粒度聚类
Facebook AI和Tel Aviv大学的研究人员提出了一种无监督的同步学习方法,包括:
- 条件图像生成器
- 前景提取和细分
- 两级层次结构分类
- 对象移除和后台完成
以上所有内容均无需使用注释即可实现。该方法将生成的对抗网络和变型自动编码器结合在一起,具有多个编码器,生成器和鉴别器,并可以即时解决所有任务。
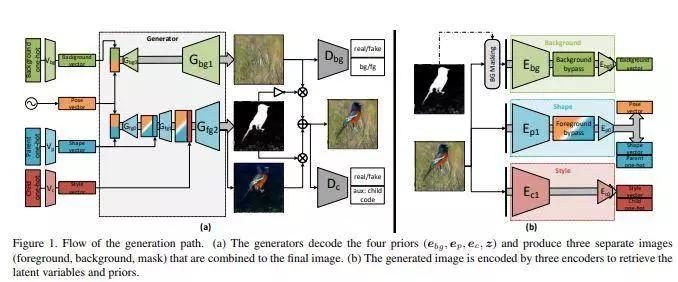
该训练方案的输入是来自同一域的未标记图像的各种集合,以及没有前景对象的一组背景图像。另外,图像生成器可以将一个图像中的背景与第二个图像或所需聚类的索引条件下的前景相混合。
通过构建单个模型来处理多个无人监督任务,研究人员在每个任务上都展现了超越同类最佳方法的性能,并展示了协同训练的能力。
与传统方法相比,该方法在每个任务中均获得了最新技术成果。
阅读更多:
https://arxiv.org/abs/1912.13471v1
从图像推断用户界面属性
为了帮助开发人员自动开发用户界面,这一研究探索了一种新的学习领域来推断用户界面属性。给定设计师创建的输入图像后,研究人员将学习推断其实现方式,该实现方式在呈现时的外观和输入图像相似。
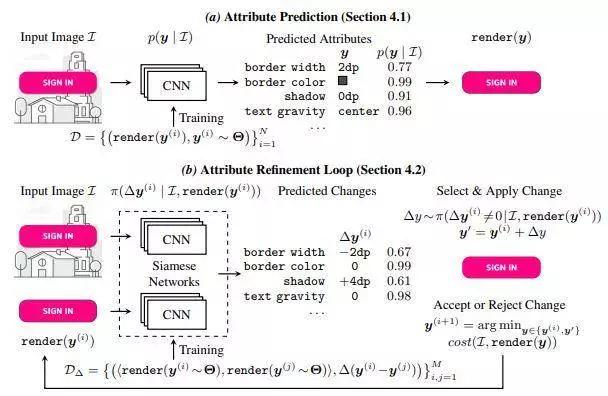
他们采用了黑盒渲染引擎及其支持的一组属性,包括颜色,边界半径,阴影或文本属性,并使用它来生成合适的综合训练数据集。然后,他们训练了专门的神经模型来预测属性值。
为了提高像素级别的准确性,研究人员使用了模仿学习来训练一种神经策略,该策略通过学习计算原始图像和渲染图像在其属性空间中的相似度,而不是基于像素值的差异来改进预测的属性值。对于合成数据集和真实数据集,该方法分别成功推断出正确的属性值分别为94.8%和92.5%。
与以前产生草图或将组件放置在所需位置的综合布局工具不同,此新工作聚焦于像素级的精确实现。
研究人员能够将其实例化为学习Android Button组件实现的任务,并在由Google Play Store应用程序组成的数据集上达到92.5%的准确性。他们表示,这一切仅需要对合适的合成数据集进行训练即可实现。该方法是实现用户界面流程自动化的重要一步。
阅读更多:
https://arxiv.org/abs/1912.13243v1
用于查询高效主动模仿学习的新框架
这项工作提出了一种新的模仿学习(IL)算法框架,该算法可通过有效查询主动交互地学习用户回报值模型。研究人员建立了一个对抗生成模型来生成状态和一个后继特征(SR)模型,通过学习策略收集的过渡经验来训练这些模型。
本文提出的方法使用这些模型来选择状态-动作对,要求用户对最优性或安全性进行评论,并训练对抗神经网络来预测回报值。
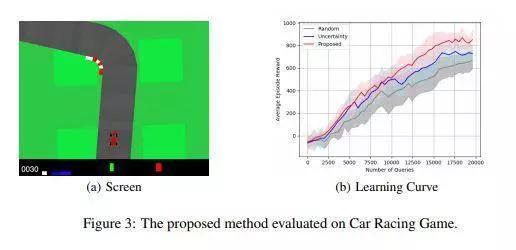
以往论文几乎全部基于不确定性抽样,而本文则与此不同。本文的关键思想是通过区分查询的(专家)和未查询的(生成的)数据,并最大程度地提高价值函数学习的效率,来主动且高效地从on-policy和off-policy的经验中选择状态-动作对。
该方法在学习回报模型时明显优于基于不确定性的方法,从而实现了更好的查询效率。其中对抗性判别器可以使机器人更有效地学习人的行为,而后继特征模型可以选择对价值函数有更大影响的状态。该方法还可以在训练回报模型时学会了避免不安全状态,评估实际游戏时这一优势得到了验证。
原文:
https://arxiv.org/abs/1912.13037
用于对象抓取的大规模聚类和带密集批注的数据集
对象抓取对工业,农业和服务贸易中的许多应用都至关重要。然而,在聚类场景中,研究面临训练数据不足和缺乏评估基准的挑战。
在本文中,几位研究人员贡献了一个大规模的抓握姿势检测数据集,该数据集具有一个统一的评估系统,且包括大约87040张RGBD图像和3.7亿个抓握姿势。评估系统分析计算后可以直接报告抓握是否成功,它能够评估任何种类的抓握姿势,从而避免了费力标记抓握姿势真实与否。
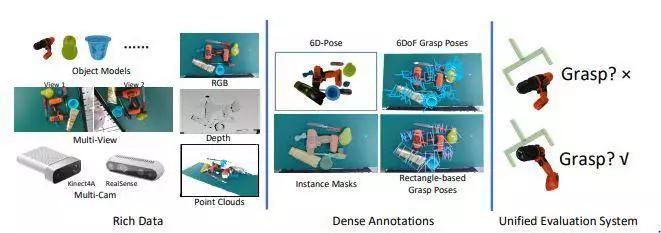
研究人员进行了广泛的实验,实验表明该数据集和评估系统都可以很好地体现现实世界的场景。
这项工作建立了一个大型数据集,可用于聚类场景对象的抓取。数据集由现实世界的传感器拍摄的图像组成,并有丰富且密集的批注。本文提出的统一评估系统将促进这一领域的发展。这种方法极大地减轻了批注抓握姿势这项工作。
将来,研究人员打算将数据集扩展到多指夹持器和基于真空的末端执行器。相关数据集,源代码和模型将很快公开提供,请留意。
原文:
https://arxiv.org/abs/1912.13470
其他爆款论文
这些最新发布的技术对于使用法医语音比较的学生和研究人员来说很重要:
https://arxiv.org/abs/1912.13242
解决视听嵌入式导航中的新问题,从而将其推广到新目标和新环境,并取得显著成效:
https://arxiv.org/abs/1912.11684
最先进的面部交换:
https://arxiv.org/abs/1912.13457v1
最近提出的这种方法在3D人形和姿势方面超越了最先进技术:
https://arxiv.org/abs/1912.13344v1
为什么深度卷积网络不能很好地推广到小图像变换?
https://arxiv.org/abs/1805.12177v4
数据集
用于文本检测和识别的数据集:
https://arxiv.org/abs/1912.11658v1
通过自然语言反馈检索图像的新数据集:
https://arxiv.org/abs/1905.12794v2
为更易实现的机器故事理解提供重要立足点的新数据集:
https://arxiv.org/abs/1912.13082v2
AI大事件
麻省理工学院的工程师提出了一种替代常规超声波的方法,该方法不需要接触身体即可看见患者体内:
https://news.mit.edu/2019/first-laser-ultrasound-images-humans-1219
当机器学习带来经济效益:
https://news.mit.edu/2019/machine-learning-sales-ebay-translation-1220
首尔将安装AI摄像机进行犯罪侦查:
https://www.zdnet.com/article/seoul-to-install-ai-cameras-for-crime-detection/

